
Practical Process Automation: How to Get Started
You need to be signed in to add a collection
Have you ever given process automation a chance? While it affects the daily life of most of the developers on the planet it has a bad reputation. One of the main reasons being that, usually, “Too much logic went into the model at these times, and that was even combined with the technology stack, which was relatively complex” Bernd Ruecker, the author of Practical Process Automation, co-founder at Camunda. Discover the benefits of process automation in an interview with Bernd and Richard Seroter, Director of Product Management at Google Cloud.
Transcript
Listen to this episode on:
Apple Podcasts | Google Podcasts | Spotify | Overcast | Pocket Casts
Join Bernd Ruecker, author of Practical Process Automation and co-founder at Camunda, and Richard Seroter, director of product management at Google Cloud, for a discussion about process automation. They’ll delve into best practices and anti-patterns after exploring the reasons you should consider doing process automation and how it can help your company.
This episode of the GOTO Book Club was possible thanks to the support of Camunda, an open-source software company innovating process automation with a developer-friendly approach that is standards-based, highly scalable, and collaborative for business and IT. Camunda is proud to partner with O’Reilly Media to sponsor Practical Process Automation, written by Bernd Ruecker, Camunda’s Co-Founder and Chief Technologist. The book explores how process automation compares to business process management, service-oriented architecture, batch processing, event streaming, and data pipeline solutions. Get a sneak peek here: http://bit.ly/38m09Ij
Intro
Richard Seroter: All right. Good to see you all. My name is Richard Seroter. I am here interviewing Bernd Ruecker here to talk about his book on "Practical Process Automation." I'm a director of product management at Google Cloud. I also do some work for InfoQ and several other channels too and spend too much time on Twitter as well. But I want to pause that today to at least spend some time with you, Bernd Ruecker, and ask you about this very interesting book. But first, please introduce yourself.

Bernd Ruecker: Hey, Richard. Thank you very much. My name is Bernd Ruecker. I'm one of the co-founders of Camunda. We're an open-source process automation company. And that's also my background. So I've been working in the field of process automation, workflow engines for the last 15 years, and contributed to a couple of open-source workflow engines in the past. And like you, I probably spend too much time on Twitter and conferences, at InfoQ and such.
Process automation: what is it and why should devs care about it?
Richard Seroter: That's okay. It's a good use of time. Although let's just jump right in here. So process automation. This can sound like something that probably most developers, programmers don't think a lot about. Maybe they don't think of it outside their code. How would you describe what process automation is really about? Why should a developer care about this?
Bernd Ruecker: Yeah, that's one of the misconceptions I have seen more often out there in the field. Why should I care as a developer? It's that kind of business thingy, right? And in essence, a workflow or a process is a sequence of steps or a sequence of tasks, and what makes it so special is typical that these tasks can be different things, especially long-running things. So I have to wait for something. That can be a human. It can be a system to respond. It can be the customer to select something. It can be an asynchronous message coming back, whatever it is, right. As soon as you need to wait for certain things, you have additional requirements because you have to save the state where you're currently at. So you can keep waiting not only for milliseconds but seconds, minutes, days, weeks, whatever it is. That's a huge problem to solve.

This is where workflow engines strive very much. While the typical use case is really in the domain of these business processes most developers think of, like whatever, order fulfillment, customer onboarding, claim settlement, and so on and so forth. It can start very small if you have typical integration problems around asynchronous messaging, around function orchestration, whatever. There are a couple of these use cases as well. That's why I believe it affects most developers on the planet probably.
Who is building workflows in a company?
Richard Seroter: Who in the company creates them, though? Is that the developer, the traditional programmer, is that a business analyst? Is that someone in the cafeteria staff? Like, who is building workflows at the company?
Bernd Ruecker: It depends a little bit on the use case, what I've just sketched. So if you're in integration problems, it might be the developer looking at these kinds of processes. But if I look more on the business side of things, it's very often a business analyst or some role that translates between business and IT. It's not always called a business analyst. And the reason why that's possible with process automation is that most of the tools work with visual modeling. Then you have original models of the sequence of steps, and that helps… that facilitates collaboration. You can discuss the model. You can clarify a lot of things on the model. That also means you can talk about the model and the problems with a lot of different people. And that's normally in the domain of business analysis.

But it also helps, and that's my experience, with integration use cases, even on a very technical level. So I saw a lot of use cases where developers discuss with developers, where the other person also didn't understand what they're saying until you sketch something on the whiteboard. Then it got clear. The whole idea is to take that model as a kind of executable code so you can model that thing graphically. But at the same time, that's executable code that it can give to a workflow engine. And then you always have the model or the documentation that is in sync with reality, which is a huge thing to achieve.
How do you decide what goes in the model vs the code?
Richard Seroter: You mentioned this in the book, which everyone should pick up and read. It's a great book. But how do you start to decide what goes in the model or what goes in the code? Right? Because I've spent my year as well doing a lot of process orchestration. You accidentally start throwing a lot of loops or conditionals here in the model. How can a developer think about what belongs in my function or my component or my service? What do I outsource to the workflow engine?
Bernd Ruecker: I think that's an area where a lot of mistakes were made in the past, were too many things went into the model, with earlier waves, and that normally left the developers behind saying, "Why should I model this? I can code it much faster. It's much better in code." For me, it's kind of the default as it goes into the code. That's my default. Then there are exceptions why I should put it in the model. And the main reasons are either I need the persistent state, so there are steps I need to wait for something. Then it goes into the model. Then I might have to decide the granularity I want to have. Like, I could have one step in the model, and this, in the background does whatever, three REST calls. That means one of these phases I keep will be in that one step, if I want to have the first REST call succeed and if I want to kind of record that persistently, and then I need to have three activities in the model as well.

So whenever I need to wait, whenever I want or I need to discuss that very often, that's kind of a more practical thing, but I have that regularly that certain questions are asked all the time. Like somebody sees the model, he's like, how do you do that? That's written in the code.
Then it's very often handy to just add it to the model because then you save a lot of time discussing it. The third reason is typically you want to analyze uncertain audit data the virtual engine writes. So you want to analyze, how often did we go that way, under which circumstances do we make the decision that way or the other? These are the three reasons normally why you put stuff in the model and everything else should go to the code. Like that, it works pretty, pretty nicely. That's something that was often not done right in the past, and why a lot of developers also have a wrong view about process automation.
Why does process automation have a bad reputation?
Richard Seroter: Do you think it’s tied to… you know, you and I have been around for a little while with this stuff. The old enterprise service buses and service-oriented architectures, and some of these big BPMN engines at the time, is where that reputation kind of came from? Is it just this big sort of distant thing that didn't have source control, or I couldn't continuously deliver it, or it's just a separate beast? Do you think that reputation has kind of impacted people's thoughts today?
Bernd Ruecker: Yes, totally. So the one reason is what you just said. There was this kind of beast sitting over there. This was kind of one of the problems, it was very often very centrally managed. It was a different team. So if I'm, for example, a team caring about order fulfillment, I might have to deploy a piece of code for my order fulfillment logic. But I might also need to deploy some rules on an enterprise service bus. I might need to deploy a process on that BPM system over there. Everything is managed by different people, different technologies. And that was pretty hard to do and pretty hard to get right, almost impossible to test, and this kind of thing. So that didn't work out.

The second thing is connected to what you just asked. Too much logic went into the model at these times, and that was even combined with the technology stack, which was relatively complex. I mean, at that time, SOAP was kind of the order of the day and XML. I like XML, so nothing against XML. But that whole combination was pretty complex. That left a lot of people to… it just doesn't work out. And in a mixture with, and that probably came on top of that, with big vendors ruling that field and throwing in what they called low code and tools sold by the idea of, hey, you don't need developers to automate that process. You can click it together, which, for a weird reason, doesn't work, it still doesn't work. That pulled a lot of developers away from the area of process automation being something for them, which is a pity.
How to make a system workflow-friendly?
Richard Seroter: Yes. So if I am a developer today thinking about how I connect to, let's say, an existing monolith, existing commercial software, what are a couple of things I might need to do to make that system workflow friendly? How do I play with that other ERP system or that other… even custom-built them? What's the kind of table stakes? What do I need?

Bernd Ruecker: Yes, it depends on the situation at hand. I always have this very handy here at my desk. I mean, normally I do something, I called that pain trim development sometime back. I'm not sure if that's unique. I mean, you don't always need some kind of a pain to create a project which has some impact on the company. So when you see something that needs to change in the monolith, in the legacy, and whatever you have, that might be a good opportunity to look outside workflow automation or more modern tools around workflow automation and say, hey, look, instead of burying that again in the monolith, let's put that into some own service. Let's build a proper process model. Let's integrate that with the monolith and probably other systems. That sounds relatively easy. It's super hard in reality because that normally requires that you have to cut a lot of things under the hood of the monolith. You have to provide a couple of facades for the process to call, and so on, so forth. But I think that's a good way of going about that. Then you slightly really just dismantle the monolith into smaller pieces. Or you might have functionality that's relatively independent of the monolith. And making the model is like one system is being used. That's sometimes possible, especially in end-to-end scenarios. There, you have that, whatever, customer onboarding process, and you might need the monolith, but you might also need the CRM system, or whatever.
Use cases of embedded engines
Richard Seroter: That makes sense. So if we start thinking about the actual development experience… You talk about some different workflow engine types, and there can be an embedded engine that might even be part of my code or a library I add to my app, your workflow as a service, which I'm interacting with remotely. How do I start to decide between things like that? Give me an example the developer might recognize of an embedded sort of engine.
Bernd Ruecker: So I mean, that's kind of where we are currently coming from. In my reality, in my daily life, the embedded engine was kind of the default for the last 10 years. So that works. It's a library. It's a Spring Boot startup, for example. You just add, and then the workflow engine is started up as part of your application, just needs a database to persist things.

It's very easy to use, very lightweight. I still like the model for certain situations, especially if you build a kind of monolithic software, or we have software vendors building their product but using a virtual engine as part of it. That makes a lot of sense. As an industry, we're slightly moving towards using more as-a-service components. I mean, that's not only true for virtual engines but everything. The cloud pushes it towards that. I think you pretty much know about that. But it makes a lot of sense if you're more familiar with that environment, and I think people are getting more and more familiar, either with public cloud or on-prem cloud, just services that it can provision easily for a certain use case.
And as soon as you have that, it makes a lot of sense to have the virtual engine as part of a resource that you just provision if you need it. Because then you don't have to think about, okay, how do I configure the workflow engine? How does it even persist? How can I tune it for my workload? I have persistence problems, and so on. One of the common themes in support for us in the last 10 years was really like figuring out the exact configuration of the whole Spring Boot application, of the transaction manager, of this and that, and whatever connection pools to figure out what the problem is. With the managed service, you can isolate this kind of problem. So I find that the better way of running it. As an industry, we're just moving towards that. So most development teams out there are not ready for that yet, but I expect that to change over the next few years.
Orchestration vs choreography
Richard Seroter: Now, if I am that developer and I'm thinking about... And again, we've seen this for a long time now, this discussion between orchestration and choreography of maybe I'm just chaining together a bunch of services through an event bus. Maybe I'm using Kafka, and I'm just spinning up different things and maybe putting some metadata in a header that says this is the next thing to do, whatever it might be. What are some pros, cons? How would I decide? I want to just kind of do a decentralized model where nobody knows what's going on in the big picture, but it's very lightweight and flexible, agile versus a more coordinated, centralized workflow engine. How do I decide that?
Bernd Ruecker: Yeah, that's one of the questions I'm thinking about most, actually, because I came up with it a couple of years back when event-driven architectures were new. I mean, they are not new, but then, Kafka gained traction, and a lot of people started to apply these. And I had some very serious discussions around like, hey, why do I need that workflow engine again? We want to be decoupled. We want to be flexible. We just do it event-driven. And I thought about that quite long and discussed that with customers in their scenario.
Let's quickly introduce both concepts because I think that it's easier to follow. So the idea of an event-driven system, of the so-called choreographed approach for order fulfillment, would have some component that says, hey, somebody ordered something, that could be an order placed event, put on a bus. And that component doesn't know anything who picks it up. Then there might be another component like the payment service, for example, say, hey, if there was an order placed, I might have to collect money for that.
There might be another service, a shipment service that knows, okay, now I have to collect all the goods and put it in a parcel, or have some person do that and ship it out and so on, so forth.
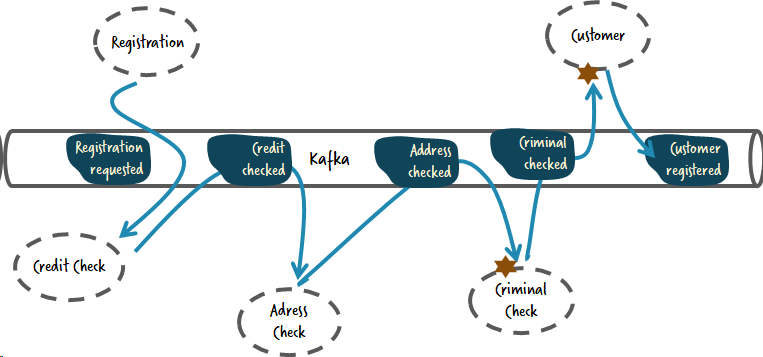
By doing that, the overall business process emerges out of different event subscriptions. The problem with that, and we saw that with a lot of customers by now is that the whole process emerges. It's hard to understand it. There's a good article now from Martin Fowler, he wrote, you lose sight of a larger scale flow. I think I even remember a tweet from you saying something along the lines of control flow must go somewhere.

The problem is then really you can probably observe it during runtime, but you have no idea to look into the code to understand how things are going. And also, it's very hard to change the process behind that because now we have to look at a couple of different components, change event subscriptions, and the chain belongs together, and that's not super easy to do.
So whenever there's a real business process, a real flow logic behind it, I find it much more logical and much easier to have that in one place and saying, okay, look, this is the process. This is how it looks. Then I can also have a clear owner for that because that's sometimes… that's the thing that puzzled me the most in the beginning. Like we have Zalando, for example, as a customer in Europe, they're quite big for shipping clothes. They're doing every order fulfillment process over our software. And it's really weird to imagine that they let the order fulfillment emerge out of certain event notifications. Like, oh, if we're lucky, it happens. If we're lucky, it happens within the SLA. That's kind of a weird thing.
The problem starts unfolding because you can't easily look into how this is implemented. You can't easily understand the process or the flow as it's currently implemented. That's one of the problems that has a couple of more problems like it's hard to change if you don't understand it. It's hard to foresee all the problems you might run into. I also see one other problem, like it's hard to dedicate ownership or responsibility to that. Because if you have that chain of events, you can't say, okay, one of the components is responsible, but it's kind of the behavior emerging at runtime is responsible. That's hard to say, why did that order didn't ship within, like, a certain time frame, right?
There is a contrast as you go with a workflow engine with the process automation approach. That means you have that logic expressed in a process model. It doesn't meet central. That's an important piece of the puzzle, for me. It means that I might have that one order fulfillment team and a micro-service context being responsible for order fulfillment. They might express certain things by a process model to orchestrate like other components. I find that much more natural because then you can understand the process, you can analyze it. You can understand a lot of aspects and data around that, and you have that one place to go if it doesn't work, for example.
When does a choreography model make sense?
Richard Seroter: Are there cases where that choreography model does work for you, for like certain types of processes where you do want that just daisy-chaining of things, or almost unrelated, who knows what happened before? Does that ever make sense to you?
Bernd Ruecker: Yes. I mean, what I also describe in the book is that I think you need a balanced approach. So there are certain use cases where events make a lot of sense. An example of order fulfillment would be notifications. I don't want to want to think about when to send notifications exactly in each and every process. I can simply subscribe to certain events and send them out. That makes a lot of sense. I've seen it used very successfully in, let's say, startup situations where you have to move very fast and you build logic on top, then it might be easier to work with the events in the beginning. From my perspective, it adds technical debt. You have to pay back at some point in time, but that can be a good decision in the beginning if you have to move fast. It's normally not that good of a decision if you're kind of a big company getting your core processes right. So there are certain use cases where event-driven makes a lot of sense, and especially if you don't have this logical flow of events. It's much less risky to use events for that.
How to use workflows to improve business metrics
Richard Seroter: Now, one thing you talked about in the book related to that was, and you mentioned earlier with having an owner and thinking about the bigger process, was using workflow, sometimes to capture and improve some business metrics? Because now I am looking at an end-to-end flow. So, how does that work? Especially from spanning different systems. How have you seen or what would be a case where I'm using workflow to bubble up maybe metrics that matter more?
Bernd Ruecker: Yes. I find it one of the most interesting fields of the current development because there is not an out-of-the-box solution yet from, I think, any vendors. So there are a couple of different angles where we can tackle it. Like, microservices do a lot of things from the tracing or observability point of view. But that's very often very technical to understand, like, the pain point of microservices. We have process mining, which very often looks at, how can we scrap log files from your ERP systems, for example, to understand certain things? So not so much at really runtime behavior. We can make a lot of sense from the workflow engine data we write. And we teach the component a little bit to understand other events, to get a perspective on the end-to-end monitoring. But it's also not yet where I think it should be, so there's still innovation happening especially on understanding the whole end-to-end thing that normally spans different technology stacks. Adding the business perspective on top of that is super interesting.
Richard Seroter: Yes, it seems like a nice way to maybe break folks out of their siloed metrics, like maybe my system is doing okay, but the whole process is broken. I don't know if you've seen that where sometimes you see different metrics bubble up because you're looking at the whole process for the first time.

Bernd Ruecker: Absolutely. We did a couple of experiences now where we extended the view from only what was automated on the workflow engine to end-to-end. And that revealed a lot of surprises.
Best practices for process automation
Richard Seroter: All right. A couple more questions for you. So I'm sure there's plenty of ways to do this wrong. So, what are some anti-patterns? What are things people should be looking out for going, "Hey, I thought I was doing process automation right? I thought I was using a cloud workflow engine correctly," and you would look at that and go, "that is a bad idea." So what are things, some land mines that we should be avoiding now, whether we're using, again, an embedded library, whether we're using a cloud-hosted service, your product, what are some traps we should watch out for?
Bernd Ruecker: I'm biased. You should use our product. That's a good idea. Or if you're already looking at workflow engines, I think that's the most important step in the beginning because I see bespoke, homegrown, own engines super off, and that's a lot of effort you have to put into. So don't do that. Don't build your engine. And that normally starts with, hey, we don't need a workflow engine. We don't have the requirements for that. And that's very often not true. So I find that the most important part.
Then the second part for me is language, like what workflow engine and what process modeling language do I use on top of that? And you mentioned the cloud workflow engines, the cloud products. They all have their proprietary language. And for a couple of reasons, I'm not a super big fan of it. I'm a huge fan of BPMN, that's ISO standard. That's very much understandable. It's kind of the English process modeling languages. So I would look for something that supports it for various reasons. I go into much detail in the book.

Then that's kind of, I think, obvious, but use it for the right job, the right tool for the right job. So don't do graphical programming with the workflow engine. Don't go for local tools if you have core processes to automate, and so on, so forth.
Richard Seroter: Yes. And as you mentioned, maybe not throwing too much business logic in there, or I don't know, it seems like there's plenty of ways you could overdesign it or overuse it, and accidentally have a maintenance nightmare.
Bernd Ruecker: The interesting part is, I've seen it both ways. So I've seen workflows that were like one task. This is where all the magic happens. That doesn't make any sense. And the other way round doesn't make any sense either.
How to get started with process automation
Richard Seroter: All right. Last thing I want to ask you. Someone's listening to this, going, "All right, process automation doesn't sound like it's just the dusty old thing that somebody outside of IT does. This sounds fun. I should look at it more." How do you get started with this stuff? If you've mostly just been writing Java code, Go code, C# code, and you're not used to this idea of abstracting that out to workflow, or maybe you've been doing implicit workflow. Maybe you've built your own almost accidentally. How do you get someone started there? How do you say, these are the things to start looking at, these are the things to start trying? And then win over the people in your workplace who might be skeptical of this model.
Bernd Ruecker: Yes that's a very, very good question. So the first thing just gets going. That's always my advice. Try it out. I mean, select the tool. Happy if you choose ours. Happy if you choose any other. Do kind of a POC. I mean, first play with it, and then try to get to a proof of concept quickly in the company. Like something not too small, not too big, that it can do some severe work. And then normally we use that show-and-tell approach. Like, hey, we have something awesome here, this helps us. Then we talk to people in most of the companies where our tools are adopted on a broad basis, it started with the champion that went around and told everybody, hey, this is what we did, this is why it was awesome, this is where you can look at the code and try it out yourself. So I'm much in favor of this kind of approach. It's like try it out. Rainy, rainy Saturday. Give it a go. It's not that complex. You should be able to get something running within hours. It's not days, it's hours.
Richard Seroter: Is there an obvious use case for someone getting started that says, hey, look, I'm trying to do order intake. I'm trying to do something from a web-flow, or I'm building nothing but cloud functions, and I want to start coordinating them. Is there something where you could say this is low-hanging fruit, go after this first? Don't show me you are, it's the pen thing again.
Bernd Ruecker: How did you anticipate that? No, but I would take whatever is familiar to you as a developer. Like, if you are all day into whatever function, then probably function orchestration is the best use case for you because that's the environment you know. So I would do that. If you have no idea and wanna do anything, we very often do approval processes, because they're boring, but they have all the important things. They have a human task. They have a decision point. You can add some service tasks in there. There are get-started guides you can follow. You simply follow them. No, it depends.
An investment case for workflow automation
Richard Seroter: Ok. And then the last part of that, though. But if I am trying to win over my skeptical colleagues, are there metrics around workflow operations that stand out? Whether it's a cost of an ownership thing, is the visibility of the end-to-end process. How do I go show, let's say my boss, and say, hey, this is worth the investment in time? Are there one or two metrics or things that bubble up from a workflow that they should lean on?
Bernd Ruecker: There are a couple of things. You very often can look into either time savings or cost savings because you automate certain things. Very often if you look at it from a technical perspective, it's “do I understand my process, and am I able to change it later on?” So it's more, can I still survive the next year's kind of thing? Which is harder to put in numbers. But sometimes it's easy. We have a couple of examples. For example, from a bank. They did a product in, like, two months, and they had savings of, what was it, $10 million every year. So if you're lucky, you have that use case where you can calculate it super, super quickly. But most of the time you might not have it. I have that one picture in the book where I look at the return on investment. I think it is also… it depends on the investment.
What we see nowadays, it's not that you have to buy a huge tool suite and get months of training before you're productive. You can get going very quickly, and that also reduces the barrier very much.
Richard Seroter: Yes, of course. Well, awesome. Thanks for taking some time to run through these questions. Folks who are listening, you should pick up "Practical Process Automation." It's a good book. I enjoyed it. Well, easy to read. And I picked up a few things myself. So thanks, Bernd, for taking the time. And hope folks enjoyed the conversation we got to have here.
Bernd Ruecker: Thanks, Richard..
About the authors
Bernd Ruecker is a software developer at heart who has been innovating process automation deployed in highly scalable and agile environments of industry leaders such as T-Mobile, Lufthansa, ING and Atlassian. He contributed to various open-source workflow engines for more than 15 years and he is the Co-Founder and Chief Technologist of Camunda – an open-source software company reinventing process automation. He is the author of "Practical Process Automation" and co-author of "Real-Life BPMN". Additionally, he is a regular speaker at conferences around the world and a frequent contributor to several technology publications. I focus on new process automation paradigms that fit into modern architectures around distributed systems, microservices, domain-driven design, event-driven architecture, and reactive systems.
Richard Seroter is Director of Outbound Product Management at Google Cloud, with a master’s degree in Engineering from the University of Colorado. He’s also an instructor at Pluralsight, the lead InfoQ.com editor for cloud computing, a frequent public speaker, the author of multiple books on software design and development, and a former 12-time Microsoft MVP for cloud. As Director of Outbound Product Management at Google Cloud, Richard leads a team focused on products and customer success for app modernization (e.g. Anthos). Richard maintains a regularly updated blog on topics of architecture and solution design and can be found on Twitter as @rseroter.
Recommended talks
Balancing Choreography and Orchestration • Bernd Rücker
Automating Processes in Modern Architectures • Bernd Rücker
3 Common Pitfalls in Microservice Integration & How to Avoid Them • Bernd Rücker
About the speakers

Co-founder & chief technologist at Camunda